Something keeps showing up in the AI space: companies are taking the tools they built for themselves and turning them into products other people can buy.
It usually starts as an internal fix. A team hits a problem, builds something to solve it, and over time that “something” quietly becomes good enough to sell. And the reason these tools tend to be strong isn’t luck — they’ve been shaped by years of messy, real-world use: actual data, actual operational headaches, actual feedback from people relying on them every day. That lived-in quality is hard to fake, and it’s exactly what most market-first products are missing.
But building the product is only half the story. Scaling it is where things get hard. Which raises the question this article is really about: what creates a durable AI competitive advantage — the technology, the proprietary data, or the talent to build with it?
Table of Contents
- The Quiet Pattern: Internal Tools Becoming Products
- Why These Tools Are So Good
- Where It’s Already Happening
- Building Is Only Half the Battle
- The Three Real Advantages
- The Talent Bottleneck
- A Real Example: Tools Forged by Use
- Best Practices for Turning a Tool Into a Product
- Common Mistakes
- So What Wins: Technology, Data, or Talent?
- Frequently Asked Questions
- Conclusion
The Quiet Pattern: Internal Tools Becoming Products
The most interesting AI products of the last few years didn’t start as products. They started as internal tooling — a script, a dashboard, a model, a workflow — that a team built because they were in pain and needed relief.
That origin matters. A tool built to win a market is shaped by a pitch deck. A tool built to survive a Monday is shaped by reality. By the time the second kind is “productized,” it has already absorbed a thousand edge cases that a market-first competitor hasn’t even discovered yet.
Why These Tools Are So Good
Internal tools carry an unfair advantage: they were forged by use, not by speculation.
- They’ve handled real, messy data — not the clean sample in a demo.
- They’ve survived real operational headaches — outages, weird inputs, angry users.
- They’ve absorbed continuous feedback from people who depend on them daily.
This is essentially a head start on the feedback loop that every product eventually needs. The internal tool spent years quietly compounding that learning before anyone tried to sell it. That compounding — often called a “data flywheel” — is the part competitors can’t simply copy, a point a16z makes about the economics of AI businesses.
Where It’s Already Happening
You can already see the pattern across industries, with companies wrapping up their AI capabilities and offering them as platforms:
| Domain | Internal need that became a product |
|---|---|
| Hiring | Resume screening and candidate matching |
| Customer support | Ticket triage and automated responses |
| Procurement | Spend analysis and vendor evaluation |
| Healthcare | Documentation, coding, and triage assistants |
| Business operations | Forecasting, reconciliation, and workflow automation |
In each case, the company didn’t set out to build a SaaS product. They set out to fix their own bottleneck — and the fix turned out to be valuable to everyone with the same bottleneck.
Building Is Only Half the Battle
Here’s where the story usually gets harder than people expect. Shipping a working prototype is one thing. Turning it into something that holds up in production — for thousands of customers, with reliability, security, and support — is another entirely.
Production-grade AI demands a different set of muscles:
- Reliability: handling traffic spikes, degraded models, and bad inputs gracefully.
- Evaluation: knowing whether the model is actually getting better, not just different.
- Data pipelines: clean, governed, and continuously refreshed (the same discipline behind lean data engineering).
- Security and privacy: especially when the proprietary data is the moat.
- Cost control: inference is not free, and margins disappear quickly without it.
A prototype proves the idea is possible. Production proves the idea is a business.
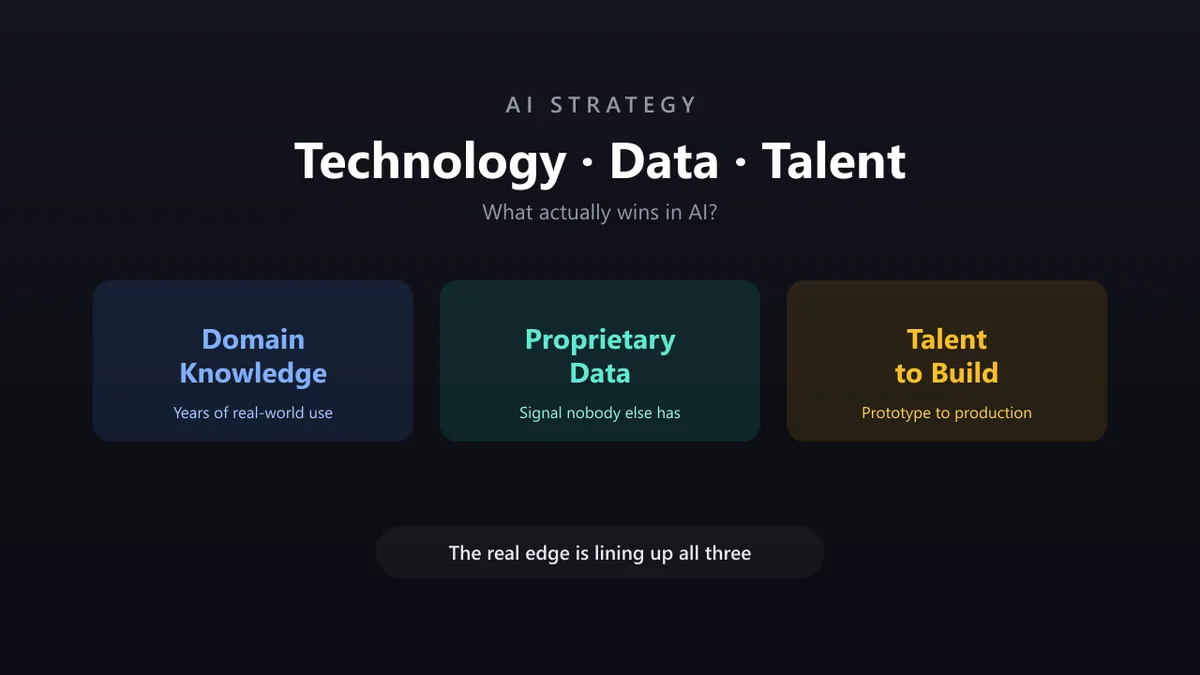
The Three Real Advantages
If you strip the hype away, durable AI advantage tends to come from three sources — and the strongest companies have all three, not one.
1. Domain Knowledge
Knowing the problem deeply is what tells you which 5% of the work actually matters. Domain knowledge is why an internal tool fits its niche so well: the people who built it are the users. It’s the hardest advantage for an outsider to reverse-engineer.
2. Proprietary Data
Models are increasingly commoditized; the data you train and evaluate on is not. Proprietary data is the closest thing to a real moat in AI, because it’s the one input a well-funded competitor can’t simply buy. Andrew Ng’s data-centric AI movement makes the same case: improving the data often beats improving the model.
3. Talent to Build With It
Domain knowledge and data are inert without people who can turn them into a product that scales. This is the advantage everyone underestimates — and, right now, the scarcest of the three.
The Talent Bottleneck
Here’s the uncomfortable truth: AI adoption is growing far faster than the supply of people who can actually do this work. Surveys like the Stanford AI Index and the McKinsey State of AI show adoption climbing every year, while the World Economic Forum’s Future of Jobs report keeps flagging the widening skills gap.
So the real bottleneck might not be coming up with the idea. It might be finding the engineers, data scientists, researchers, and platform teams who can take a promising prototype and turn it into something that holds up in production. Ideas are cheap; the people who can ship them reliably are not.
A Real Example: Tools Forged by Use
This pattern isn’t abstract — it’s how a lot of the best developer tools are born, too. Take a QA engineer who keeps hitting the same wall: browser tests that fail for reasons users never experience, mobile bugs that are impossible to reproduce, APIs that drift out of contract. Instead of buying a tool that doesn’t fit, they build one that does.
That’s the origin of OrbitTest: a testing platform that started as a fix for everyday QA pain — intent-first browser automation, Android testing in OrbitTest Studio, and API testing in OrbitTest Client — and grew because it was shaped by real workflows, not a market spec. The same three forces apply: domain knowledge (knowing exactly what QA teams struggle with), data (what real test runs and failures look like), and the talent to turn it into something dependable.
Best Practices for Turning a Tool Into a Product
If you’re sitting on an internal tool that might be a product, a few things separate the ones that make the leap from the ones that stall:
- Protect the data advantage. Treat your proprietary data as the asset it is — govern it, secure it, and build the flywheel that keeps it fresh.
- Invest in evaluation early. You can’t scale what you can’t measure. Define how you’ll know the AI is actually working before you onboard customers.
- Hire for production, not demos. The skill that builds a prototype is not the skill that keeps it up at 99.9%. Bring in platform and reliability talent sooner than feels comfortable.
- Keep the domain experts in the loop. The people who felt the original pain are your best product compass — don’t sideline them once “real” product managers arrive.
- Control inference cost from day one. Margins are a feature. Cost discipline decides whether the product is a business.
Common Mistakes
- Confusing a demo with a product. A great prototype convinces a room; production convinces a market.
- Assuming the model is the moat. Models commoditize fast. Data and domain depth don’t.
- Under-hiring the unglamorous roles. Data engineering, evaluation, and platform work are where AI products live or die.
- Ignoring feedback once you “ship.” The flywheel that made the internal tool great only keeps spinning if you keep listening.
- Scaling before it’s reliable. Growth on top of a shaky foundation just multiplies the incidents.
So What Wins: Technology, Data, or Talent?
It’s tempting to pick one. But the honest answer is that any single advantage is fragile:
- Technology alone gets copied.
- Data alone sits unused without people to build with it.
- Talent alone, without proprietary data or domain depth, is just expensive horsepower pointed at the wrong problem.
The companies that pull ahead in the next few years probably won’t be the ones with a single edge. They’ll be the ones who manage to line up all three at once: deep domain knowledge, data nobody else has, and the talent to actually build with it. The technology is the table stakes; the combination is the moat.
Frequently Asked Questions
What is the biggest competitive advantage in AI?
There isn’t a single one. The most durable AI competitive advantage comes from combining deep domain knowledge, proprietary data, and the engineering talent to build production-grade products. Any one of these alone is relatively easy for a competitor to match.
Why are internal tools often better than market-first AI products?
Because they’re shaped by years of real-world use rather than speculation. They’ve already handled messy data, operational edge cases, and continuous user feedback — learning that a product built purely for the market hasn’t accumulated yet.
Is proprietary data really a moat?
It’s the closest thing to one. Models are increasingly commoditized, but the data you’ve collected and the way you evaluate on it are hard to replicate. Whoever has unique, well-governed data has an advantage that funding alone can’t buy.
Why is talent the bottleneck in AI right now?
AI adoption is growing faster than the supply of people who can build and scale it. Coming up with an idea or a prototype is comparatively easy; finding engineers, data scientists, and platform teams who can make it reliable in production is the hard part.
What’s the hardest part of turning an AI prototype into a product?
Production readiness — reliability, evaluation, data pipelines, security, and cost control. A prototype proves the idea works once; a product proves it works for thousands of users, consistently, at a sustainable cost.
How do I start turning an internal tool into a product?
Protect and govern the data that makes it valuable, invest in evaluation so you can measure quality, hire for reliability early, and keep the domain experts who built it close to the roadmap.
Conclusion
The pattern is clear: the strongest AI products are often internal tools that were quietly perfected by real use before anyone thought to sell them. But building the tool is the easy half. Scaling it into something dependable is where most attempts stall — and that’s a talent problem as much as a technology one.
So when you ask what wins in AI — technology, proprietary data, or talent — the most honest answer is all three, together. The next few years will reward the companies that can line them up at the same time.
What’s your bet? When you look at the AI products pulling ahead, does it come down to the technology, the data, or the people who build it?
Written by Abhay Kumar — QA engineer and creator of OrbitTest, writing about engineering, AI, and building tools that hold up in the real world. Browse more AI & Engineering articles.
