Ask a developer to write unit tests today and there’s a good chance they’ll open ChatGPT before they open their test file. It’s fast, it’s fluent, and it produces something that looks like a test suite in seconds. But does it produce a suite you can trust — and does leaning on it change how you test?
A 2026 study in Empirical Software Engineering set out to answer exactly that. Baris Ardic, Quentin Le Dilavrec, and Andy Zaidman of TU Delft ran an observational study of 12 developers writing unit tests with ChatGPT, capturing every prompt, every screen action, and a post-task interview. What they found is one of the most grounded pictures we have of how people actually use generative AI for testing — not the marketing version.
This article distills the study into the parts that matter for your own workflow, credits the original research, and turns the findings into practices you can apply on Monday morning.
Key takeaways
- Developers fall into four strategies, defined by whether the test idea and the implementation come from the human or the AI (C1–C4).
- Heavy AI reliance (C1) strongly correlates with one-shot prompting; manual workflows (C4) lean on iterative prompting.
- The most common AI failure was a subtle wrong assertion — a plausible-looking expected value that was simply incorrect. Every one-shot user had to fix generated tests by hand.
- AI was good at test ideas, weak at exact implementation. Its biggest measured benefit was reduced cognitive load, not raw speed.
- Prompting style and strategy did not produce measurably better or worse test quality (by coverage, mutation score, or test smells) in this sample.
Table of Contents
- The study, in one paragraph
- Four strategies: who owns the idea, who owns the code
- One-shot vs iterative prompting — and why they cluster
- The catch: AI nails the idea, fumbles the assertion
- Did AI actually make the tests better?
- What developers gained — and gave up
- How to apply this to your own workflow
- Frequently asked questions
- Conclusion
The study, in one paragraph
The researchers recruited 12 university students who had all completed a mandatory software-testing course — a deliberate stand-in for novice testers who know the theory but haven’t yet hardened their habits. Each wrote unit tests for two short Java methods drawn from Apache Commons Lang (initials() and substringsBetween()), free to use the browser version of ChatGPT (running GPT-3.5) however they liked. The team recorded screens, ran a think-aloud protocol, and interviewed each participant afterward, then coded the behaviour with two raters (Cohen’s Kappa of 0.75, “substantial” agreement). The full paper is open access: How students use generative AI for software testing.
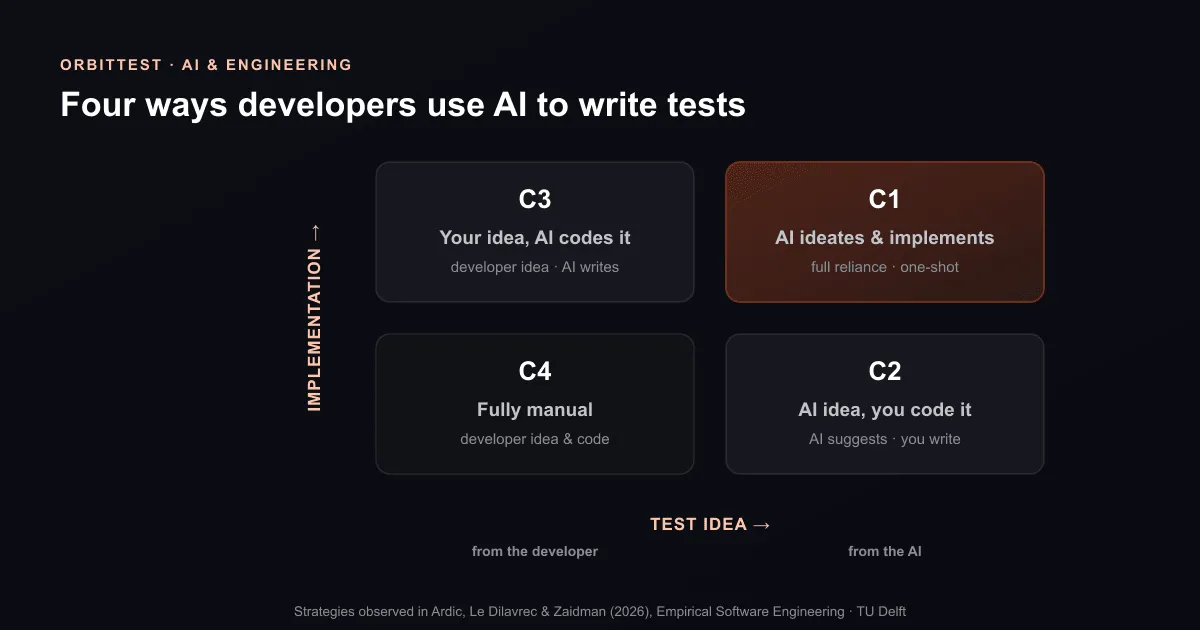
Four strategies: who owns the idea, who owns the code
The study’s central insight is that AI-assisted testing isn’t one behaviour — it’s four. Every unit test involves two distinct acts: coming up with the idea (what should this test check?) and writing the implementation (the actual assertion code). Either can come from you or from the AI, which produces a clean 2×2:
- C1 — AI ideates and implements. You ask, “write me a test suite,” and take what comes back. Full reliance.
- C2 — AI idea, you implement. You ask the AI for cases to consider, then write the code yourself.
- C3 — Your idea, AI implements. You know exactly what to test and use the AI as a fast typist to generate the code.
- C4 — Fully manual. No AI in the loop for either step.
About half the participants used C1 in at least one task, making it the most common approach; C4 (traditional, manual testing) was second. The intermediate strategies — C2 and C3 — turned out to be the interesting ones: they let a developer offload part of the work while keeping a hand on the wheel. The study frames these as natural control-preserving moves, and they’re the ones worth adopting deliberately.
One-shot vs iterative prompting, and why they cluster
Layered on top of the strategies is how people prompt. The researchers found two distinct styles:
- One-shot: ask for a complete test suite in a single prompt.
- Iterative: build the suite through a sequence of smaller, focused prompts and refinements.
These aren’t random. Developers who relied heavily on the AI (C1) overwhelmingly favoured one-shot generation — 9 of 10 C1-dominant assignments used it. Those doing more of the work themselves (C4) leaned iterative, because that style let them course-correct and stay in control between prompts. In other words, how much you trust the AI and how you talk to it are two sides of the same coin.
Across all 12 participants the team logged 111 prompts (about 9 per assignment). The dominant purpose was test generation (72 of 111), but ChatGPT also served as a quick explainer of code and syntax (32 combined) and an occasional refactoring tool. Interestingly, the most common piece of context people supplied was the entire source file (57 prompts) — a reminder that good output still depends on good input.
The catch: AI nails the idea, fumbles the assertion
Here’s the finding every developer should internalise. When the AI got a test wrong, it was rarely because the test idea was bad. It was because the expected value in the assertion was subtly incorrect — a value that looks completely plausible until you trace the code by hand.
The initials() method returns the first character of a string plus the first character after each delimiter. Ask ChatGPT to test it with a colon delimiter and you get something like this:
// ChatGPT's generated assertion — looks reasonable, but it's wrong
assertEquals("CST", initials("Customer: Service: Team", ':'));
// Corrected: the characters right after each ':' are spaces,
// so the real result is 'C' followed by two space characters
assertEquals("C ", initials("Customer: Service: Team", ':'));The model assumed each capitalised word contributes its first letter — a very human, very wrong guess. Because “Service” and “Team” sit after a space that follows the colon, the true initials are spaces, not letters. This kind of quiet mismatch was the single most common error type, and critically: every participant who used one-shot generation had to manually fix the generated tests. A test that passes because its expected value was reverse-engineered from buggy assumptions is worse than no test at all — it’s a false sense of safety.
The flip side is genuinely encouraging: the study reports that the test ideas the AI proposed were generally sound, and participants frequently kept them. The takeaway is a division of labour — trust AI for what to test, verify it yourself for what the answer should be. This is exactly why structured, deterministic techniques like boundary value analysis and equivalence partitioning remain valuable: they give you expected values derived from rules, not guesses.
Did AI actually make the tests better?
Yes and no — and the nuance is the point.
Compared to a pre-AI baseline, yes. The same two methods were used in an earlier study of professional developers who worked without AI (Aniche, Treude & Zaidman, 2022). The AI-assisted participants produced test suites with higher line coverage and better mutation scores — averaging ~89% mutation score versus ~79% for the pre-AI professionals, and writing more tests on average (12 vs 9 per person). Access to a capable assistant clearly helped.
Between strategies, no. Within the study itself, neither the strategy (C1–C4) nor the prompting style (one-shot vs iterative) produced statistically significant differences in test effectiveness or in test smells — the researchers ran a Mann–Whitney U test and, given the small sample, found no clear winner. They analysed the suites with the open-source TSDetect tool and saw the usual suspects (Assertion Roulette, Eager Test, Magic Number Test, and others), but no approach was systematically cleaner than another.
The practical reading: with AI in reach, how you drive it mattered less for the final numbers than the simple fact that you had a competent assistant. But “no measured difference in a 12-person study of simple methods” is not the same as “it doesn’t matter” — and the assertion-error finding shows precisely where the risk hides on harder code.
What developers gained, and gave up
The interviews surfaced a consistent ledger of benefits and drawbacks.
| Reported benefit | Mentions |
|---|---|
| Saves time | 13 |
| Reduced cognitive load | 10 |
| Developer supervises the AI | 8 |
| AI acts as a supervisor/guide | 6 |
| Test generation assistance | 6 |
| Reported drawback | Mentions |
|---|---|
| Lack of quality (misses edge cases, duplicates) | 13 |
| Lack of trust in output | 9 |
| Lack of ownership over the tests | 6 |
| Loss of skill / prevented learning | 2 |
Two things stand out. First, the biggest benefit wasn’t raw speed — the study found AI didn’t dramatically cut the time to write an assertion — it was reduced cognitive load. AI is good at clearing the blank-page problem and the boilerplate, freeing attention for judgement. Second, lack of quality was tied for the most-mentioned theme overall, and “lack of ownership” is the quiet one to watch: when you didn’t write a test, you feel less accountable for whether it’s correct, and you’re more likely to accept it without scrutiny. That’s the mechanism by which weak tests slip into a suite.
How to apply this to your own workflow
The study offers a conceptual framework: the right amount of control depends on your experience and the task complexity. Low-experience developers on simple tasks can lean on one-shot generation safely; as either dimension rises, you need to reassert control. Translated into concrete habits:
- Split the two jobs on purpose. Use AI for ideation (ask “what edge cases am I missing for this method?”) and keep verification of expected values for yourself. This is the C2/C3 sweet spot the study highlights.
- Prefer iterative prompting on anything non-trivial. Small, focused prompts give you natural checkpoints to catch a wrong assertion before it’s buried in a 20-test dump.
- Never trust a green assertion you didn’t reason about. The most dangerous test is one that passes for the wrong reason. Trace at least the boundary cases by hand.
- Derive expected values from rules, not vibes. For input validation, generate cases from constraints with a boundary value and equivalence partitioning generator so the “correct answer” comes from the spec, not the model’s guess.
- Protect ownership. Review AI-written tests as strictly as a colleague’s pull request — because functionally, that’s what they are. Our take on this mindset is in intent-first testing.
- Automate the ones that survive. Once you trust a set of cases, run them on every build — drive them as a data-driven run so they execute in CI instead of by hand.
For a broader view of what to automate versus test by hand, see our QA automation test strategy guide.
Frequently asked questions
Is it safe to use generative AI to write unit tests?
It’s safe for ideation and boilerplate, and risky for final assertions. The study found AI’s test ideas were generally sound, but its most common mistake was a subtly incorrect expected value that still compiled and could pass trivially. Always verify the expected outputs yourself, especially on edge cases.
What are the four AI test strategies (C1–C4)?
They’re defined by who supplies the test idea and who writes the implementation: C1 (AI does both), C2 (AI suggests the idea, you code it), C3 (you supply the idea, AI codes it), and C4 (fully manual). C2 and C3 are the balanced, control-preserving middle ground.
Should I use one-shot or iterative prompting for tests?
One-shot (asking for a whole suite at once) is faster but was linked to heavy AI reliance and always required manual fixes. Iterative prompting — smaller, focused requests — gives you checkpoints to catch errors and is the better default for anything beyond trivial code.
Does AI-generated test code have more test smells?
In this study, no strategy or prompting style produced statistically more test smells than another. Common smells like Assertion Roulette and Eager Test appeared across the board, so treat AI output with the same review standards you’d apply to any test code.
Does using AI to write tests hurt learning?
The study of already-trained developers found no drop in test quality, suggesting AI is a safer fit when you’re practising known skills rather than acquiring them. Participants did report a diminished sense of ownership, which can reduce the reflection that deepens understanding.
Conclusion
The clearest signal from this research is a division of labour: generative AI is a strong collaborator for test ideas and a shaky one for exact implementations. It lowers the cognitive cost of getting started, it broadens the edge cases you consider, and — measured against a pre-AI baseline — it helped developers write more effective suites. But it also produces plausible, wrong assertions that pass silently, and it quietly erodes your sense of ownership over the result.
Use it the way the study’s most effective participants did: let it draft, keep control of the verification, prompt iteratively when the code gets hard, and derive your expected values from rules rather than the model’s best guess. Do that, and AI becomes a genuine multiplier instead of a false sense of coverage.
Credits & references: This article summarises and interprets Ardic, B., Le Dilavrec, Q., & Zaidman, A. (2026). How students use generative AI for software testing: An observational study. Empirical Software Engineering, 31:167, published open access under CC BY 4.0. Read the original: doi.org/10.1007/s10664-026-10898-0. The authors’ replication data package is available on figshare. Related tools and standards referenced: Apache Commons Lang, PIT mutation testing, TSDetect, and the ISTQB test-design techniques.
Written by Abhay Kumar — QA engineer and creator of OrbitTest, building practical tools for browser, mobile, and API testing. Browse more AI & Engineering articles.


